🚀 LIMIT: Less Is More for Instruction Tuning Across Evaluation Paradigms
Aditi Jha, Sam Havens, Jeremey Dohman, Alex Trott, Jacob Portes
Princeton University, MosaicML x Databricks
aditijha@princeton.edu, jacob.portes@databricks.com
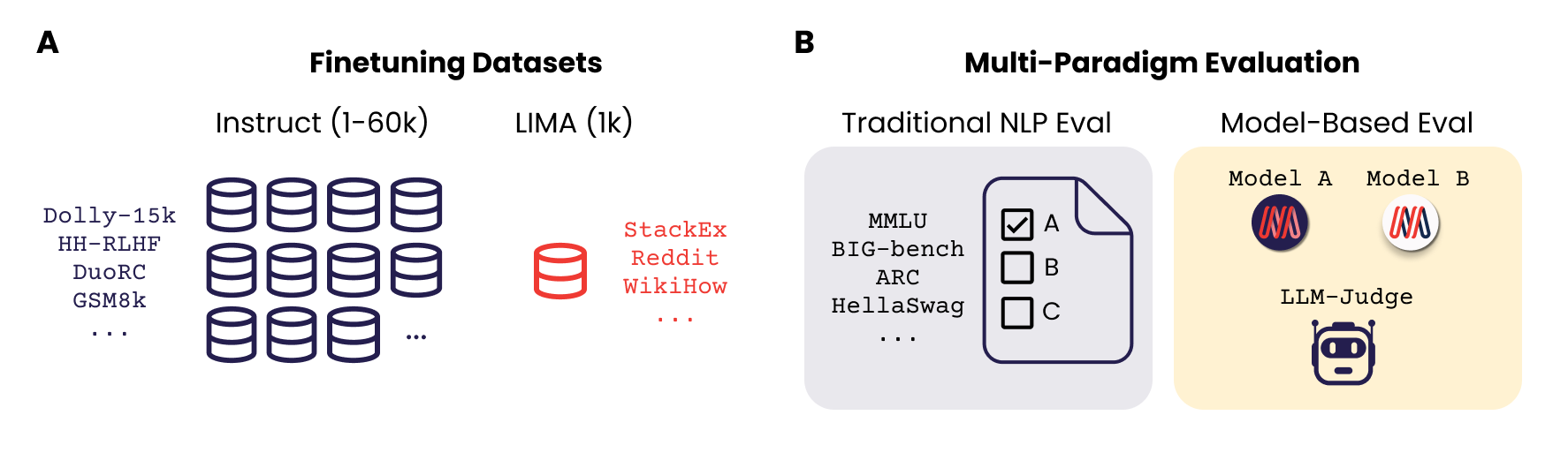
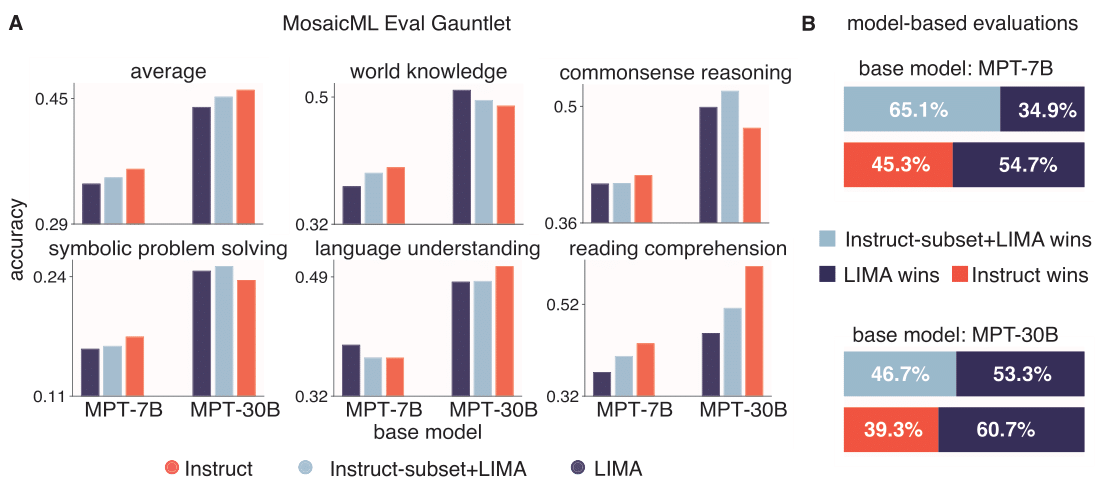
Large Language Models are traditionally finetuned on large instruction datasets. However recent studies suggest that small, high-quality datasets can suffice for general purpose instruction following. This lack of consensus surrounding finetuning best practices is in part due to rapidly diverging approaches to LLM evaluation. In this study, we ask whether a small amount of diverse finetuning samples can improve performance on both traditional perplexity-based NLP benchmarks, and on open-ended, model-based evaluation. We finetune open-source MPT-7B and MPT-30B models on instruction finetuning datasets of various sizes ranging from 1k to 60k samples. We find that subsets of 1k-6k instruction finetuning samples are sufficient to achieve good performance on both (1) traditional NLP benchmarks and (2) model-based evaluation.
Finally, we show that mixing textbook-style and open-ended QA finetuning datasets optimizes performance on both evaluation paradigms.
@article{jha2023limit,
title={LIMIT: Less Is More for Instruction Tuning Across Evaluation Paradigms},
author={Aditi Jha and Sam Havens and Jeremy Dohmann and Alex Trott
and Jacob Portes},
journal={arXiv preprint arXiv:2311.13133},
year={2023},
}